
I never lose. I either win or learn.
Mea culpa
Vous vous dites qu’il y a un problème ? Vous vous attendiez à un article sur Sundesk, mon travail ou peut-être sur l’amour ? Eh bien, non, enfin pas tout à fait. Pour tout vous dire, j’avais prévu de faire un article sur la vie à Sundesk, mais j’ai rencontré deux problèmes. Le premier problème était ce que je redoutais depuis le début du lancement de mon blog : avoir le syndrome de la feuille blanche. C’est désormais chose faite et, même si je tremble en écrivant ces lignes, car je ne sais pas si je vais arriver à pondre un article qui sera buvable, pas trop technique et compréhensible même par votre grand-mère, je vais donner le meilleur, comme à chaque fois ! 😉
Le deuxième problème était que… eh bien Sundesk, il y a beaucoup à dire, mais il faut avoir une certaine ambiance, un certain moment où je sais que j’ai beaucoup de choses à dire, mais là, sur le moment, ce n’était pas le cas. Cela vient s’ajouter aux problèmes de propriété intellectuelle lorsque j’ai rédigé mon plan d’écriture. Oui, parce que c’est bien joli d’écrire à propos d’un sujet qui peut me passionner, mais Sundesk est une entreprise, avec des gens, et tout ce beau petit monde n’a pas tellement envie de voir sa tronche être utilisée dans le blog d’un développeur moyen, qui plus est, un blog qui n’est pas encore très connu. Alors, par conséquent, j’ai basculé sur un sujet qui me passionne et dont j’avais envie de parler enfin : j’ai bien évidemment nommé Proxmox !
Rassurez-vous, un jour il y aura bien un article sur Sundesk et mon travail, il sera fait et bien… peut-être le jour où je n’y travaillerai plus, qui sait ? Oui, parce que le moment où on peut prendre le plus de recul avec une situation ou quelque chose, c’est quand cette chose ne fait plus partie de notre vie. Cela est similaire à n’importe quelle chose dans la vie, que ce soit un travail, une passion, un projet ou même une relation. Bref, je m’égare, mais vous voyez l’idée : il faut parfois prendre du recul pour pouvoir parler de quelque chose de manière plus objective et plus complète. En attendant, je vais vous parler de Proxmox, mon amour, mon bébé, ma passion, mon tout ! (sans abus)
 Photographie promotionnelle du prochain centre d’affaires Sundesk à Valbonne (2026)
(Crédit photo : Sundesk)
Photographie promotionnelle du prochain centre d’affaires Sundesk à Valbonne (2026)
(Crédit photo : Sundesk)
Le début d’une grande histoire d’amour
Je connais Proxmox depuis 10 ans, c’est bien évidemment faux. Dans ma tête de tech’, Proxmox est un outil que j’ai découvert grâce à mon travail et qui, au début, m’effrayait ou dans lequel je voyais peu d’intérêt : un outil obsolète utilisé par des gens probablement bien plus compétents que moi, un outil qui ne me servirait jamais pour héberger de pauvres sites Internet. J’avais tort. Quand je l’ai découvert au travail, il servait à créer des machines virtuelles pour tout un tas de choses : exécuteurs GitLab, machines de contrôle Ansible, preuves de concept (PoC), environnements d’essai pour éviter de taper directement sur la production et bien d’autres choses. Et puis, je m’y suis intéressé, parce que cela faisait déjà quelques années que je faisais de l’administration système, pour mes besoins comme pour ceux d’autres personnes, mais encore à l’ancienne : une machine physique ou virtuelle chez un hébergeur, un Debian ou un CentOS en fonction des demandes, l’environnement adéquat et en avant Guingamp.
Eh oui, j’ai appris comme ça à administrer des serveurs Linux sans interface graphique. Il y a une dizaine d’années, on m’avait confié la tâche d’installer un serveur Garry’s Mod sur une machine CentOS obsolète d’un ami qui n’avait pas le temps de le faire. Une fois sa confiance accordée et les accès root en main (notez qu’il n’a pas hésité une seconde à les donner à quelqu’un de novice 😬), j’ai installé, sans Docker ni orchestrateur, un serveur Garry’s Mod… et ça a fonctionné (youpi ?). Cela m’a fait découvrir le monde des serveurs : SSH, dépendances, gestion du pare-feu pour ouvrir le port 27015, etc. Bref, l’une des expériences les plus enrichissantes que j’ai pu vivre à mon jeune âge, en dehors de mon premier script en Lua ou de ma première leçon de conduite. C’est à ce moment-là que j’ai compris que je venais de trouver une passion supplémentaire en plus du développement.
 Photographie promotionnelle du jeu vidéo Garry’s Mod (2006)
(Crédit photo : Facepunch Studios)
Photographie promotionnelle du jeu vidéo Garry’s Mod (2006)
(Crédit photo : Facepunch Studios)
Il a fallu ensuite attendre quelques années avant que j’aie les moyens de me prendre des serveurs, d’abord virtuels (A.K.A. les VPS) chez OVH, puis des machines dédiées sous Debian pour gérer mes premières infrastructures. J’ai commencé à administrer mes serveurs à distance, sécuriser mes installations, faire des sauvegardes, installer Apache puis Nginx quand j’ai vu les tendances arriver, et l’utiliser comme serveur mandataire inverse pour héberger mes sites Internet. Puis j’ai découvert Docker, ce qui m’a permis de faire évoluer mes techniques de déploiement, passant de scripts bash en SSH à des déploiements plus modernes avec Docker et des pipelines CI/CD sous GitHub Actions. En regardant en arrière, je me rends compte que j’ai évolué doucement, mais sûrement vers des pratiques beaucoup plus modernes, efficaces et rapides.
Un serveur Minecraft ? Très bien, LinuxGSM avec Docker, on ouvre les ports nécessaires et c’est parti. Un serveur Garry’s Mod ? Docker aussi, avec une configuration adaptée. Un site Internet ? Nginx en reverse proxy avec SSL, et c’est parti. Bref, j’ai appris à faire tout ça de manière autonome, en autodidacte, en lisant de la documentation, en testant par moi-même et en apprenant de mes erreurs. Cette expérience acquise avant l’arrivée des intelligences artificielles m’a donné des bases solides que j’utilise encore aujourd’hui, autant dans mon cadre personnel que professionnel, où il faut souvent savoir faire à la fois du développement et de l’administration système. C’est ce que j’aime dans mon travail : pouvoir toucher à tout, infrastructure, sécurité, développement… et rester polyvalent.
Ma plus belle réussite, c’est aussi de gagner un peu d’argent en proposant des petits services d’installation de serveurs pour des particuliers : hébergement Web, bases de données, accès à distance, etc. Attention, je ne suis pas AWS ou Google Cloud, ni un hébergeur professionnel, juste un passionné qui aime faire ça pour le plaisir (un peu pour l’argent aussi, si possible 💸) et pour aider les autres. C’est une activité que j’aime beaucoup et qui me permet de partager mes connaissances avec des personnes qui en ont besoin.
Maintenant, voyons comment Proxmox est entré dans ma vie !
Mais Proxmox, c’est quoi ?
Minute papillon, avant de commencer à comparer ce qu’il y avait avant et ce qu’il y a maintenant, c’est peut-être le bon moment d’expliquer ce qu’est Proxmox et de faire un petit lexique de termes et d’expressions techniques qui vont ou qui peuvent être utilisés dans cet article, pour que tout le monde puisse suivre et comprendre ce dont je parle, même les personnes qui ne sont pas forcément familières avec le monde de l’administration système ou de la gestion d’infrastructure.
D’abord, qu’est-ce qu’un serveur ? Un serveur, c’est un ordinateur qui fournit des services à d’autres ordinateurs ou à des utilisateurs. Il peut être physique, c’est-à-dire une machine matérielle dédiée à cette tâche, ou virtuel, c’est-à-dire une machine virtuelle qui fonctionne sur un serveur physique. Un serveur peut héberger des sites Internet, des bases de données, des applications, des jeux en ligne, etc. Même l’ordinateur de votre mère ou votre téléphone portable peut être considéré comme un serveur s’il fournit des services à d’autres appareils ou utilisateurs. Ne vous fiez pas aux clichés de vous dire qu’un serveur se trouve forcément dans un centre de données lugubre, entouré d’autres serveurs, qui font un bruit monstrueux, qui émettent une chaleur insupportable, qui d’ailleurs aggrave le réchauffement climatique et pompe l’électricité de nos chères centrales nucléaires. Non, un serveur peut être n’importe où, même dans votre salon, votre chambre ou votre garage, tant qu’il est connecté à Internet et qu’il peut fournir des services à d’autres appareils ou utilisateurs.
 Photographie humoristique d’un ordinateur portable utilisé comme serveur (Crédit photo : Reddit)
Photographie humoristique d’un ordinateur portable utilisé comme serveur (Crédit photo : Reddit)
Dans ce même serveur, on peut installer un système d’exploitation, c’est-à-dire le logiciel qui gère les ressources matérielles de l’ordinateur et qui permet d’exécuter des applications. Il existe différents systèmes d’exploitation, comme Windows, que vous connaissez normalement si vous n’habitez pas dans une cave, macOS pour les fans de la marque à la pomme et Linux pour les gros nerds. Chacun a ses propres caractéristiques, avantages et inconvénients, mais pour les serveurs, on utilise généralement des systèmes d’exploitation basés sur Linux, qu’on appellera des distributions. Ces distributions partagent le même noyau, mais leur couche applicative ou technique change en fonction de l’orientation du système d’exploitation.
Par exemple, Debian est une distribution très populaire pour les serveurs, car elle est stable, sécurisée et facile à utiliser, tandis que CentOS est une distribution basée sur Red Hat Enterprise Linux, qui est également très utilisée dans les entreprises pour sa stabilité et sa compatibilité avec les logiciels commerciaux. Il existe aussi des distributions plus spécialisées, comme Ubuntu Server, qui est basée sur Debian, mais avec des mises à jour plus fréquentes et une communauté plus active, ou encore Fedora Server, qui est une distribution plus expérimentale et orientée vers les développeurs.
 Photographie promotionnelle du bureau de Debian 13 (Trixie) sous GNOME
(Crédit photo : The Debian Project)
Photographie promotionnelle du bureau de Debian 13 (Trixie) sous GNOME
(Crédit photo : The Debian Project)
Bref, vous l’avez compris, il y en a pour tous les cas, toutes les couleurs, toutes les saveurs, toutes les préférences, etc. Il y a des distributions pour les débutants, des distributions pour les experts, des distributions pour les serveurs, des distributions pour les ordinateurs de bureau, etc. Chacun peut trouver la distribution qui lui convient le mieux en fonction de ses besoins, de ses compétences et de ses préférences. Et évidemment, ces systèmes d’exploitation peuvent être utilisés avec ou sans interface graphique en fonction des besoins. En parlant d’interface graphique, je crois que je mets de côté un système plutôt utilisé, mais vous avez probablement déjà entendu parler de Windows Server, qui est la version serveur de Windows, avec une interface graphique similaire à celle de Windows pour les ordinateurs de bureau, mais avec des fonctionnalités supplémentaires pour la gestion des serveurs, comme Active Directory pour la gestion des utilisateurs, Hyper-V pour la virtualisation, etc. Bref, même Microsoft s’en mêle, c’est dire à quel point les serveurs sont importants et omniprésents dans notre vie numérique.
 Capture d’écran du bureau de Windows Server 2025
(Crédit photo : PantheraLeo1359531)
Capture d’écran du bureau de Windows Server 2025
(Crédit photo : PantheraLeo1359531)
Avec les bases posées, parlons de Proxmox. Proxmox, qu’est-ce que c’est ? Proxmox VE (Virtual Environment) est une sorte de plate-forme de virtualisation open source (en gros quelque chose qui peut être téléchargé gratuitement et utilisé par n’importe qui) et qui permet de créer et de gérer des machines virtuelles et des conteneurs. Qu’est-ce qu’une machine virtuelle ? Tout est clairement dans le nom : c’est un environnement virtuel informatique qui fonctionne comme un ordinateur classique, mais qui est exécuté sur un serveur physique. C’est comme si vous aviez plusieurs ordinateurs virtuels qui fonctionnent sur un seul ordinateur physique. Chaque machine virtuelle a son propre système d’exploitation, ses propres applications et ses propres ressources matérielles, comme la mémoire, le processeur et le stockage. Pourquoi une telle monstruosité ? Eh bien, cela permet de faire du multi-tenant, c’est-à-dire d’héberger plusieurs machines virtuelles sur un même serveur physique, ce qui est plus efficace en termes de ressources et de coûts. Par exemple, au lieu d’avoir trois serveurs physiques pour héberger trois sites Internet différents, vous pouvez avoir un seul serveur physique avec trois machines virtuelles, chacune hébergeant un site Internet différent. C’est plus économique, plus facile à gérer et plus flexible.
Ces environnements sont massivement utilisés chez des hébergeurs comme AWS, Google Cloud, OVH, Azure pour héberger des sites Internet, des applications, des bases de données, etc. Mais aussi dans les entreprises pour héberger des applications internes, des environnements de développement, des environnements de test, etc. En d’autres termes, Proxmox est une solution de virtualisation qui permet de créer et de gérer ces machines virtuelles et conteneurs de manière simple et efficace.
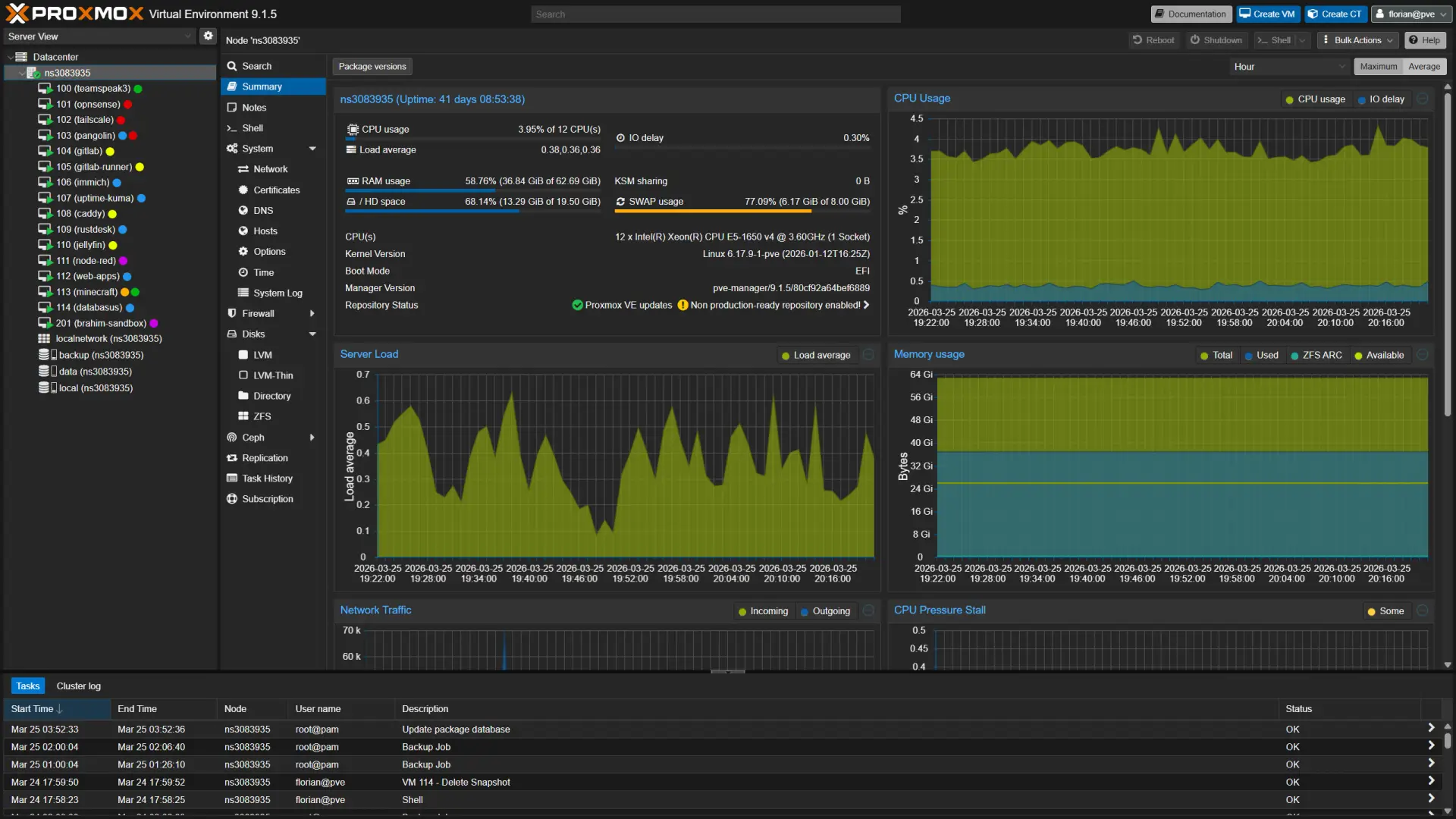 Capture d’écran du tableau de bord de mon instance Proxmox
(Crédit photo : Moi-même)
Capture d’écran du tableau de bord de mon instance Proxmox
(Crédit photo : Moi-même)
L’avantage de Proxmox, c’est qu’il est super simple à utiliser et à installer, même pour les débutants. L’avantage, c’est aussi qu’il est basé sur Debian, ce qui le rend très stable et sécurisé, et qu’il offre une interface graphique qui n’est pas au niveau du site vitrine d’Apple, mais amplement suffisante pour gérer vos machines virtuelles, votre machine hôte, vos réseaux, vos stockages, etc. Machine hôte, qu’est-ce que c’est ? C’est le serveur physique sur lequel Proxmox est installé et qui héberge les machines virtuelles et les conteneurs. C’est ce que je vous ai expliqué plus tôt : un serveur physique qui fournit les ressources matérielles pour faire fonctionner les machines virtuelles et les conteneurs.
De manière plus technique, Proxmox utilise KVM (Kernel-based Virtual Machine) pour la virtualisation complète, ce qui permet de faire fonctionner des systèmes d’exploitation complets dans les machines virtuelles, et LXC (Linux Containers) pour la virtualisation légère, ce qui permet de faire fonctionner des applications isolées dans des conteneurs. Proxmox offre également des fonctionnalités avancées comme la haute disponibilité, la réplication, les sauvegardes, les instantanés, etc. Tout ce qu’il faut pour ceux qui ont de l’argent, du temps et de l’énergie à perdre pour faire des choses qui ne sont pas forcément nécessaires pour le commun des mortels (en gros les grosses entreprises). Alors, je parle de Proxmox, mais il existe aussi une pléthore de concurrents, comme VMware vSphere, Microsoft Hyper-V, Oracle VM VirtualBox, qui offrent des fonctionnalités similaires pour la virtualisation. Je vous laisserai le loisir de décider qui est le mieux parmi eux, mais pour moi, Proxmox est la meilleure solution de virtualisation pour les particuliers et les petites entreprises, car elle est gratuite, facile à utiliser, stable et sécurisée. 💘
Bilan de l’existant
Bon, c’est très bien tout ça, mais vous vous demandez sûrement comment j’en suis arrivé à utiliser Proxmox, pourquoi j’ai décidé de migrer mon infrastructure vers Proxmox, quels étaient les problèmes que je rencontrais avant et comment Proxmox a résolu ces problèmes. Eh bien, c’est ce que je vais vous expliquer dans cette partie, en faisant un petit bilan de l’existant avant la migration vers Proxmox.
Avant, j’avais un serveur dédié chez OVH : il y avait 32 Go de mémoire, un vieux processeur Intel Core i7-7700K, 480 Go de stockage en SSD, 100 Mbit/s de bande passante, etc. C’était, disons, un serveur de milieu de gamme, catégorisé pour exécuter des serveurs de jeu, modestement, sans trop de prétention, mais malgré sa configuration limitée et vieillissante, j’ai pu installer tout ce que je voulais : Docker pour mes serveurs et applicatifs, Nginx pour mes sites Internet, des bases de données pour les accès extérieurs, WireGuard pour les accès VPN, etc. Bref, j’avais une infrastructure qui fonctionnait, qui répondait à mes besoins, mais qui avait ses limites. Lesquelles ?
D’abord, le prix : 42 euros tous les mois, ça fait mal pour une configuration qui n’est clairement pas parfaite. Ensuite, la flexibilité : je ne vous raconte pas le nombre de fois où j’ai dû faire des compromis parce que j’étais en manque de mémoire, de stockage ou de bande passante. Bref, je ne pouvais pas tout faire. L’autre gros problème était les sauvegardes. Non parce qu’OVH est bien gentil avec ses centres de données qui crament, mais la sauvegarde et la sécurité, c’est presque le b-a-ba de l’administration système, et même si la sécurité est à portée du premier gueux qui s’y intéresse, les sauvegardes, c’est une autre histoire.
 Illustration de la stratégie de sauvegarde de données 3-2-1 en informatique
(Crédit photo : Veeam Software)
Illustration de la stratégie de sauvegarde de données 3-2-1 en informatique
(Crédit photo : Veeam Software)
En premier lieu, oubliez les histoires de sauvegardes quotidiennes, répliquées à l’international pour une redondance à toute épreuve, les principes du 3-2-1, etc., régulièrement évoqués dans les communiqués de presse de l’ANSSI et de la CNIL. Ici, c’était : un script bash, rclone et on pouvait révolutionner le monde. J’utilisais deux plates-formes de sauvegarde : Mega.nz et le backup storage d’OVH. Certains vont peut-être tiquer, mais oui, j’hébergeais des sauvegardes non sécurisées sur Mega.nz, aussi connu comme étant le successeur de Megaupload, la sulfureuse plate-forme de streaming ayant fermé ses portes il y a plusieurs années. Pourquoi ? J’avais un compte gratuit de 50 Go, donc autant vous dire que je n’avais pas beaucoup de choix, et puis, c’était gratuit, donc pourquoi pas ? Pour les sauvegardes sur OVH, c’était là aussi inclus avec mon abonnement : j’avais 500 Go et j’en profitais, même si je me doutais que la redondance n’était pas forcément au rendez-vous, mais bon, c’était mieux que rien. Bref, j’avais une solution de sauvegarde qui fonctionnait, mais qui n’était pas forcément la plus fiable, la plus sécurisée ou la plus rapide, et cela m’a causé quelques problèmes par le passé, notamment lorsque j’ai perdu des données à cause d’une mauvaise configuration de rclone ou d’un bug dans mon script de sauvegarde.
Ce n’était pas si mal, et même si, après avoir expérimenté la sauvegarde via S3, j’ai pu constater que mes stratégies de sauvegarde étaient clairement à revoir, j’ai continué à utiliser mes solutions de sauvegarde, car je n’avais pas forcément le temps, ou les ressources pour mettre en place une solution plus robuste et plus fiable. Voilà une infrastructure qui fonctionnait, avec des limites et surtout beaucoup de failles, loin des standards en matière de sécurité et de sauvegarde, mais qui répondait à mes besoins à l’époque. Cependant, avec le temps, en grandissant et notamment en voulant mettre plus de moyens (fini les études, bonjour le travail), j’ai voulu faire évoluer mon infrastructure et sortir de cette catharsis qu’était mon écosystème à l’époque.
Le futur
Dans le courant de l’année dernière s’est présentée une opportunité que je ne pouvais pas refuser. Un ami travaillant au centre de données OVH de Gravelines m’a dit qu’il allait arrêter l’abonnement de son serveur qu’il avait obtenu dans le cadre de son travail et qu’il me le proposait à un prix défiant toute concurrence, même sur le site officiel d’OVH. Le serveur avait un processeur Intel Xeon CPU E5-1650 v4, cadencé à 3,6 GHz, 64 Go de mémoire, 2x480 Go de stockage en SSD en RAID-1, 2x4 To de stockage en HDD entreprise et 1 Gbit/s de bande passante. C’était une configuration de rêve pour moi, surtout pour le prix proposé (~25 €/mois, soit la moitié du serveur actuel), c’était une opportunité que je ne pouvais pas laisser passer.
J’ai donc fièrement négocié (enfin plutôt supplié) pour qu’il puisse me le laisser et, après avoir bataillé avec OVH (oui, car les salariés OVH ne peuvent pas acheter ou transférer des serveurs comme une personne extérieure à l’entreprise : il y a des vérifications supplémentaires à faire, des documents à fournir), j’ai finalement pu obtenir ce serveur et le faire transférer à mon nom. C’était une victoire pour moi : j’avais réussi à obtenir un serveur de rêve à un prix imbattable, c’était le début d’une nouvelle ère pour mon infrastructure.
 Intérieur du centre de données de OVHcloud basé à Roubaix (Crédit photo : OVHcloud France)
Intérieur du centre de données de OVHcloud basé à Roubaix (Crédit photo : OVHcloud France)
Au moment de la réception, en novembre de l’année dernière, je me suis posé la question du devenir de mon serveur actuel : son engagement se terminait en avril 2026. Je pouvais le garder une année supplémentaire, mais payer deux serveurs, ce n’était pas dans le bingo de mon année. J’ai alors fait le choix d’entamer une grande migration de toute mon infrastructure vers ce nouveau serveur, mais cette fois-ci, pas n’importe comment. J’aurais pu faire cette migration en 15 jours, en claquant Debian Server, en installant toutes mes configurations et repartir de plus belle, mais j’avais envie de faire mieux, plus proprement et plus efficacement pour l’avenir. Non parce que, dans la partie précédente, je vous ai évité de mentionner les fois où j’ai fait un rm -rf / par erreur en pensant que j’étais dans un conteneur Docker… heureusement que le ridicule ne tue pas !
Donc, quand j’ai eu le choix de réinstaller le serveur, le choix de prendre Proxmox 9 au lieu du fraîchement sorti Debian 13 était la décision qui me semblait la plus logique et profitable pour moi sur le long terme. Bien évidemment, j’ai compris que cela allait me coûter beaucoup en temps et en investissement personnel pour : apprendre à utiliser Proxmox, comprendre son fonctionnement, recréer l’infrastructure que j’avais avant, mais en mieux, faire la migration de mes projets personnels en profitant du passage pour faire du ménage dans mes projets et dans la manière dont je les gérais, etc. Bref, c’était un projet ambitieux, mais qui me tenait à cœur et qui me permettrait de faire évoluer mon infrastructure vers quelque chose de plus moderne, plus efficace et plus sécurisé.
Top départ pour quatre mois de travail acharné, de stress, de galères, mais surtout de plaisir et de gloire ! Objectif : avril 2026. 🚀
Des débuts difficiles
Les doutes
En arrivant la première fois sur l’interface d’administration Proxmox, j’ai hésité à plusieurs reprises à faire demi-tour, abandonner, à me dire que j’allais me casser le c** à faire tout ça pour, au final, me retrouver avec une infrastructure pas prête pour avril 2026. C’était aussi ce moment dans ma vie où j’ai retrouvé des personnes que j’avais perdues de vue, et j’étais assez tiraillé entre passer plus de temps avec eux et m’y investir à fond. Pour la première fois depuis un bon moment, j’avais peur, ma main tremblait, car je sortais de ma zone de confort. J’avais peur de faire des erreurs, de perdre des données, de ne pas réussir à faire fonctionner mon infrastructure. Mais je me suis projeté, j’ai écrit, dessiné, discuté avec des personnes qui s’y connaissaient un peu dans ce domaine pour qu’elles puissent me donner des conseils, des astuces, des recommandations pour que je puisse faire les choses correctement et surtout pour éviter de faire des erreurs qui pourraient être fatales pour mon infrastructure. J’ai aussi pris le temps de lire des parties de documentation officielle de Proxmox, de regarder des tutoriels sur YouTube, de participer à des forums de discussion et, sans avoir honte, d’utiliser cette fois-ci les intelligences artificielles pour m’aider à comprendre certains concepts, à trouver des solutions à des problèmes que je rencontrais, etc.
Eh bien quand vous êtes sur Proxmox pour la première fois, la première chose qui vous vient à l’esprit, c’est : « Hey, allons installer notre première VM ». Déjà, c’est un bon début, mais on vous pose plein de questions, comme : « Tu veux quoi comme système d’exploitation ? Euh, tu veux utiliser quels pools de ressources ??? Tu sais ce que tu veux comme mémoire et processeurs à allouer ??? ». Comment vous dire que j’étais plutôt perdu à me dire : « Je ne sais pas, je veux juste installer Debian », et même si la documentation officielle stipulait les ressources minimales pour le système, j’ai découvert que pour faire tourner une machine virtuelle, il fallait au moins 2 Go de mémoire et 2 cœurs de processeur (en réalité moins en fonction de l’usage), ce qui était déjà plus que ce que j’avais avant pour faire tourner mes serveurs. Et c’est là où j’ai eu le déclic qui m’a fait à nouveau douter. S’il faut 2 Go de mémoire pour faire tourner une machine virtuelle, comment je vais faire pour faire tourner mes 10 projets personnels que j’avais avant sur un serveur avec 32 Go de mémoire ? C’était là où j’ai compris que la virtualisation, ce n’était pas forcément la meilleure solution pour moi, que cela allait me coûter beaucoup en ressources, que cela allait me coûter beaucoup en temps pour faire les choses correctement et que, finalement, cela pouvait totalement foirer, car j’avais peut-être sous-estimé les ressources nécessaires.
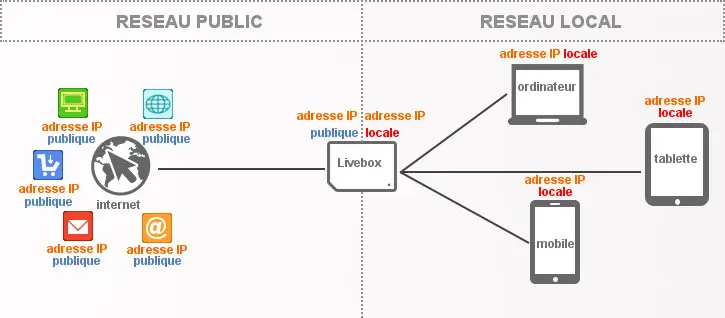 Illustration de l’adressage IP des réseaux Internet et locaux résidentiels
(Crédit photo : Orange France)
Illustration de l’adressage IP des réseaux Internet et locaux résidentiels
(Crédit photo : Orange France)
Malgré m’être rassuré en me disant que j’avais 64 Go de mémoire, que j’avais un processeur puissant, que j’avais de la bande passante, en gros que j’avais de la marge, je me suis fixé comme objectif de ne pas être gourmand, limiter au maximum, ne pas créer des machines virtuelles pour le plaisir ou qui ne me servaient à rien. Une fois la première crise de panique surmontée et l’installation de Debian réalisée, j’ai compris que je… n’avais pas accès à Internet ? Euh, dans ma tête, je pensais que Proxmox était aussi un serveur DHCP qui donnait des adresses IP à mes machines et que sa passerelle pouvait atteindre Internet les doigts dans le nez. 😎
Spoiler : non.
In the middle of difficulty lies opportunity.
Les problèmes de réseau
Oula, attendez, c’est quoi ce charabia ? Qu’est-ce qu’une passerelle ? Un DHCP ??? Okay, reprenons les bases. Votre ordinateur, pour accéder à Internet, passe par plusieurs intermédiaires, comme votre box Internet. Quand vous tapez l’adresse https://google.com, ce n’est pas magique : c’est une suite d’exécutions de protocoles et de mécanismes fondateurs du Web qui s’enclenchent. Quand vous faites « Entrée », votre ordinateur connecté à votre box Internet fait quoi ? D’abord, dans un réseau local, comprenez chez vous, chaque ordinateur a sa propre adresse IP, c’est comme son numéro de téléphone : c’est ce qui lui permet de communiquer avec les autres appareils sur le même réseau local. Cela permet, entre autres, de les joindre et de communiquer. Quand vous tapez https://google.com, votre ordinateur envoie une requête à votre box Internet pour lui demander de se connecter à Google, mais Google n’est pas sur votre réseau local, il est sur Internet. Donc votre box Internet va faire une chose essentielle : elle va être la passerelle entre votre réseau local et Internet. Elle va prendre la requête de votre ordinateur, la modifier pour qu’elle puisse être envoyée sur Internet et la transmettre à Google.
Si vous disposez de plusieurs box Internet, une de vos box peut être utilisée comme serveur passerelle et permettre à tous les réseaux chez vous de communiquer entre eux. Quand ils auront besoin d’Internet, une des box pourra utiliser sa fonction de « modem » pour faire la passerelle entre le réseau local et Internet. Une fois sur Internet, la requête de votre ordinateur va faire des bonds de serveur en serveur, de routeur en routeur, de pare-feu en pare-feu, etc., pour atteindre Google, qui lui aussi a des serveurs, des routeurs, des pare-feu, etc., pour recevoir la requête de votre ordinateur et y répondre. Bref, c’est un processus complexe qui se déroule en quelques secondes pour que vous puissiez accéder à Google, mais c’est ce qui fait la magie d’Internet.
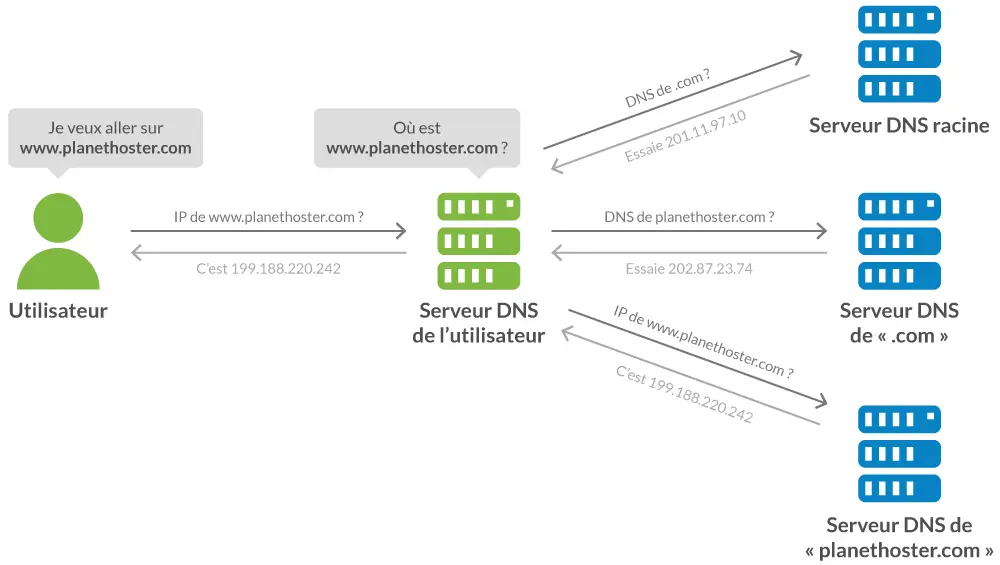 Illustration du fonctionnement des résolutions DNS
(Crédit photo : PlanetHoster)
Illustration du fonctionnement des résolutions DNS
(Crédit photo : PlanetHoster)
Bien évidemment, tout cela est très simplifié, il y a beaucoup d’autres éléments qui entrent en jeu, comme les DNS (Domain Name System) pour traduire les noms de domaine (google.com) en adresses IP (exemple : 142.251.210.78), les protocoles de sécurité pour protéger les données, les systèmes de cache pour accélérer les temps de chargement, etc. Mais l’idée générale est que votre ordinateur doit passer par une passerelle pour accéder à Internet, et que cette passerelle doit être correctement configurée pour que votre ordinateur puisse communiquer avec le reste du monde. Dans mon cas, j’avais installé Debian sur une machine virtuelle Proxmox, mais je n’avais pas configuré la passerelle pour que ma machine virtuelle puisse accéder à Internet. En allant dans les paramètres, je me suis vite rendu compte que les options de réseau étaient limitées et que Proxmox n’était finalement pas la bonne solution en l’état pour gérer le réseau interne de mes machines. Il y avait bien une option qui consistait à modifier les paramètres des interfaces réseau en ligne de commande sur le système hôte, mais je ne voulais absolument pas toucher à ça : je voulais une solution simple, rapide et efficace via interface graphique. Je ne voulais pas me prendre la tête à faire du réseau à l’ancienne, je voulais une solution moderne et facile à gérer. C’est alors que mon I.A. personnelle, A.K.A. ChatGPT, m’a conseillé d’utiliser OPNsense.
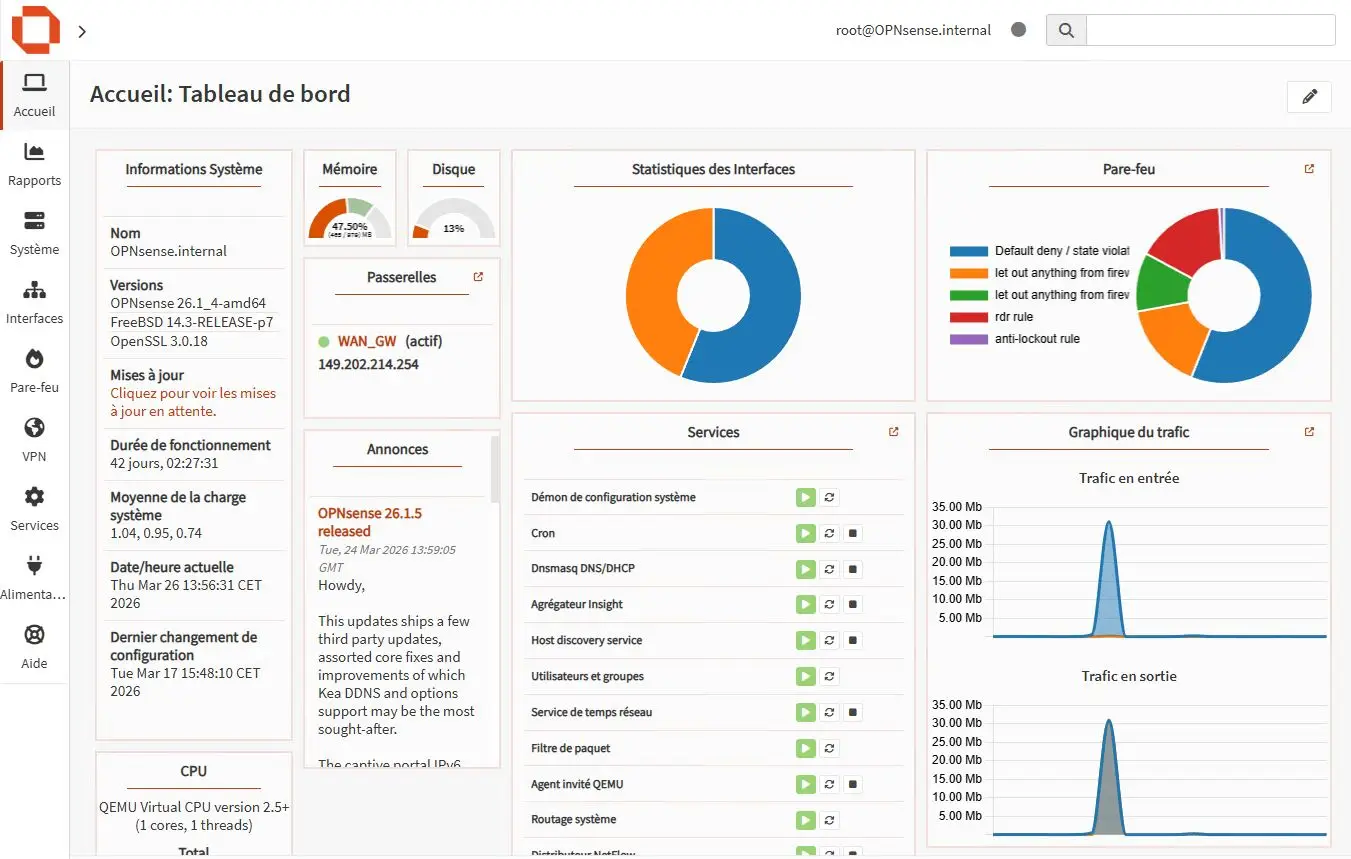 Capture d’écran de la page d’accueil du système d’exploitation OPNsense (Crédit photo : Moi-même)
Capture d’écran de la page d’accueil du système d’exploitation OPNsense (Crédit photo : Moi-même)
OPNsense, qu’est-ce que c’est ? C’est un système d’exploitation basé sur FreeBSD, qui est conçu pour être utilisé comme pare-feu et routeur. Il offre une interface graphique, plutôt jolie, pour gérer tout un tas de choses : le pare-feu, les règles de filtrage, les VPN, les VLAN, etc. C’est une solution très populaire en alternative à pfSense, qui est un autre système d’exploitation similaire, mais qui est plus orienté vers les entreprises et qui est plus complexe à utiliser pour les particuliers. Bref, c’était le Saint-Graal. Les deux seuls prérequis : avoir une machine virtuelle pour faire tourner ce système et avoir deux adresses IP dédiées. Pourquoi deux ? Eh bien, une IP serait dédiée au trafic TCP/IP de la machine hôte et pour garder un accès à la machine hôte en cas de problème avec la machine virtuelle (c’est une forme de redondance), et l’autre serait dédiée au trafic TCP/IP de la machine virtuelle, pour que les machines virtuelles puissent accéder à Internet directement sans passer physiquement par la machine hôte, c’est-à-dire que les machines virtuelles pourraient accéder à Internet directement via leur propre adresse IP, sans avoir à passer par la machine hôte pour faire le routage.
Cela présentait des inconvénients, comme le fait que je devais faire du NAT (Network Address Translation) pour que les machines virtuelles puissent communiquer entre elles et avec la machine hôte, ou au mieux créer un réseau local pour que les machines virtuelles puissent communiquer entre elles et avec la machine hôte, mais en contrepartie, les deux réseaux étaient physiquement isolés et je pouvais paramétrer le pare-feu Proxmox pour gérer les règles de filtrage pour la console d’administration, sécuriser correctement mon Proxmox et laisser OPNsense se débrouiller de la partie réseau des machines virtuelles.
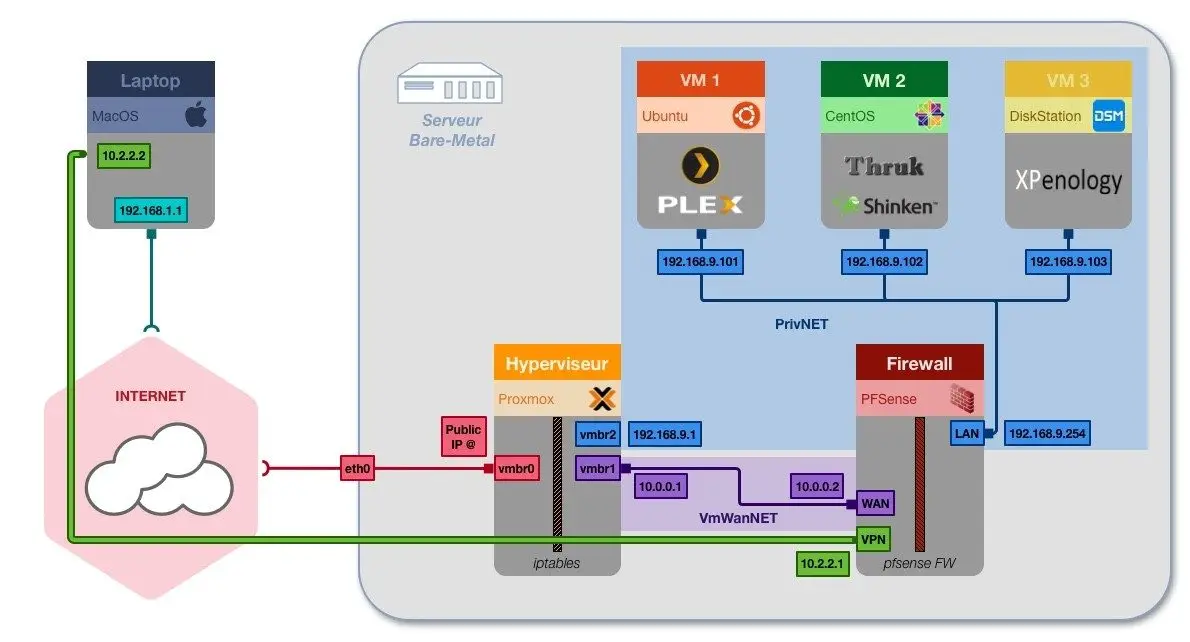 Schéma technique d’inspiration pour mon infrastructure réseau
(Crédit photo : ilip)
Schéma technique d’inspiration pour mon infrastructure réseau
(Crédit photo : ilip)
Bon, après avoir acheté une adresse IPv4 supplémentaire chez OVH, fait le lien entre ma machine chez OVH et ma machine virtuelle, j’ai créé une interface réseau appelée vmbr1 dans Proxmox et qui sera utilisée seulement pour le réseau local des machines virtuelles, dissocié de la machine hôte qui utilise, lui, vmbr0, créé par défaut lors de son installation. Dans ma nouvelle interface réseau, j’ai pu activer le serveur DHCP (en gros, pour faire comme à la maison avec laquelle chaque nouvel équipement se voit attribuer une adresse IP locale), le pare-feu pour empêcher d’exposer mes machines virtuelles sur Internet sans passer par la case pare-feu d’OPNsense, etc. Bref, j’ai pu configurer mon réseau à ma sauce et le résultat est juste satisfaisant à voir aujourd’hui. À partir de là, j’ai ressenti une très grande fierté et cela m’a levé l’ensemble des doutes que j’avais initialement : à savoir le coût de l’achat de cette IP supplémentaire, le temps passé à configurer correctement OPNsense, Proxmox & co, etc. Bref, c’était un moment de victoire pour moi, une très belle et mémorable.
La magie de la virtualisation
Après l’épisode et la partie réseau, c’était le coup d’envoi de la création de mes machines virtuelles : une VM pour mon serveur TeamSpeak 3 où mon clan se rassemble pour comploter le soir, une VM pour Pangolin, qui est le successeur direct de Nginx et qui s’appuie sur Internet sur le très célèbre Traefik, une VM pour Tailscale qui me permettait facilement, gratuitement, et comme un jeu d’enfants, d’accéder à mon réseau interne depuis n’importe quel équipement. Ensuite, j’ai remis en place mes serveurs de jeux (Minecraft, Garry’s Mod), remis ma médiathèque de films et musiques avec Jellyfin, mon serveur statique Caddy pour servir mes quelques fichiers honteux que je veux exposer au monde de manière temporaire, ma page de statut Uptime Kuma, mes photos en provenance d’Immich et tout un tas d’autres projets persos que je veux cacher au reste du monde. Néanmoins, il y a deux machines virtuelles très importantes qui ont été créées : GitLab et celle de mes sites Internet personnels.
Alors, on va décortiquer tout ce charabia. Pangolin, qu’est-ce que c’est ? C’est un serveur mandataire inverse (reverse proxy) qui permet de faire la façade entre Internet et des machines virtuelles qui peuvent exposer des applications et/ou des sites Internet. En d’autres termes, c’est un serveur qui reçoit les requêtes des utilisateurs sur Internet et qui les redirige vers les machines virtuelles qui hébergent les applications ou les sites Internet. C’est un peu comme un videur dans une boîte de nuit : il vérifie la requête HTTP que vous faites, si vous êtes sécurisé, si vous n’êtes pas bizarre, si vous ne venez pas trop fréquemment, et il vous laisse entrer pour accéder à l’application ou au site Internet que vous voulez visiter. Pangolin s’appuie sur Traefik, qui est un équivalent plus moderne et populaire que les serveurs Web traditionnels Apache ou Nginx, et la cerise sur le couscous, c’est que Traefik est presque plug-and-play avec l’utilisation de Docker, un système de conteneurisation qui permet de faire tourner des applications dans des conteneurs isolés (j’y reviens plus tard !).
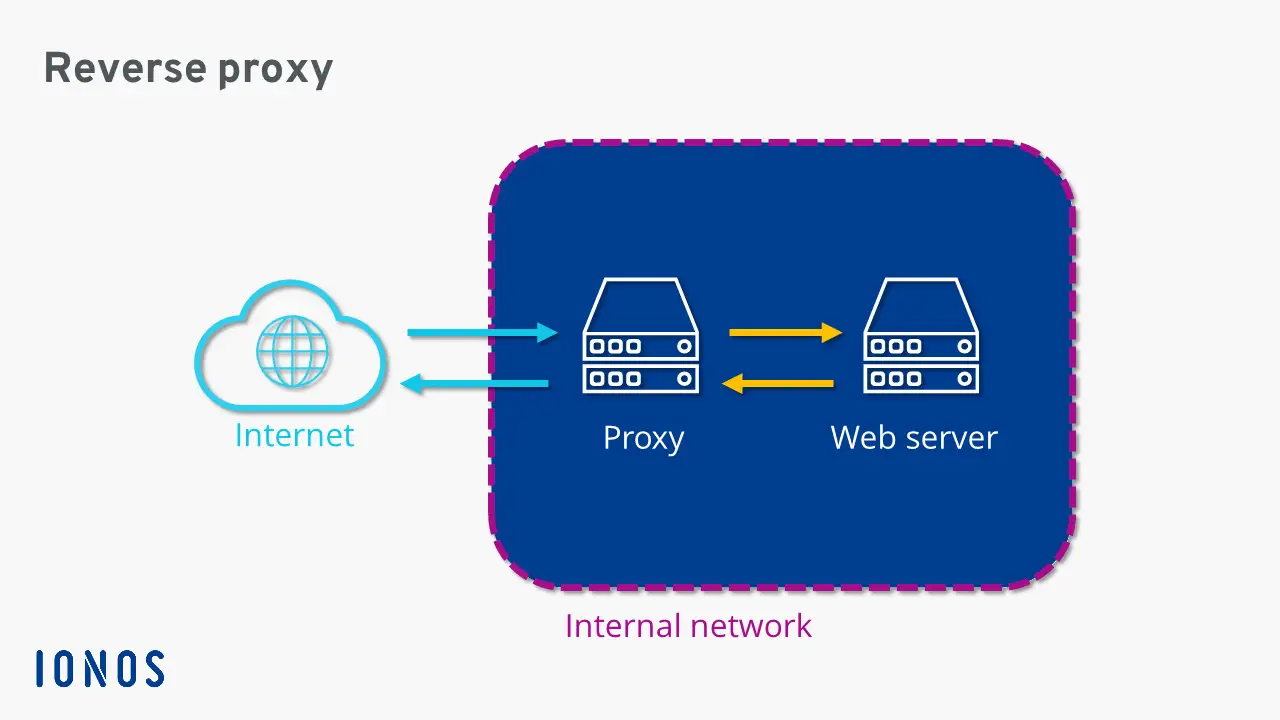 Illustration du fonctionnement d’un serveur mandataire inverse (proxy)
(Crédit photo : IONOS France)
Illustration du fonctionnement d’un serveur mandataire inverse (proxy)
(Crédit photo : IONOS France)
En ce qui concerne Tailscale, c’est ma solution à WireGuard : c’est plus ou moins un VPN qui s’appuie sur son protocole, avec une surcouche graphique et une gestion des utilisateurs plus simple, plus moderne et plus efficace que WireGuard, qui est un protocole VPN très populaire pour sa simplicité (et franchement, je pèse mes mots), sa sécurité et ses performances. Jellyfin et Immich sont tous deux des alternatives open source à Google Photos et Google Vidéos, pour héberger gratuitement et chez soi l’ensemble de ses contenus numériques sans restriction, sans publicités, sans censure, sans espionnage, bref, c’est chez vous. Uptime Kuma, c’est un outil de surveillance qui permet de vous harceler si l’un de vos sites Internet ou applications est en panne, c’est un peu comme votre mère qui vous appelle pour savoir si vous avez mangé, mais là, c’est pour savoir si votre site Internet est en ligne ou pas. Bien sûr, en plus contraignant que votre mère, car il peut vous envoyer des notifications sur votre téléphone, votre ordinateur, etc. En résumé, c’est un outil de surveillance qui vous permet de rester informé de l’état de vos sites Internet et applications, pour que vous puissiez réagir rapidement en cas de problème.
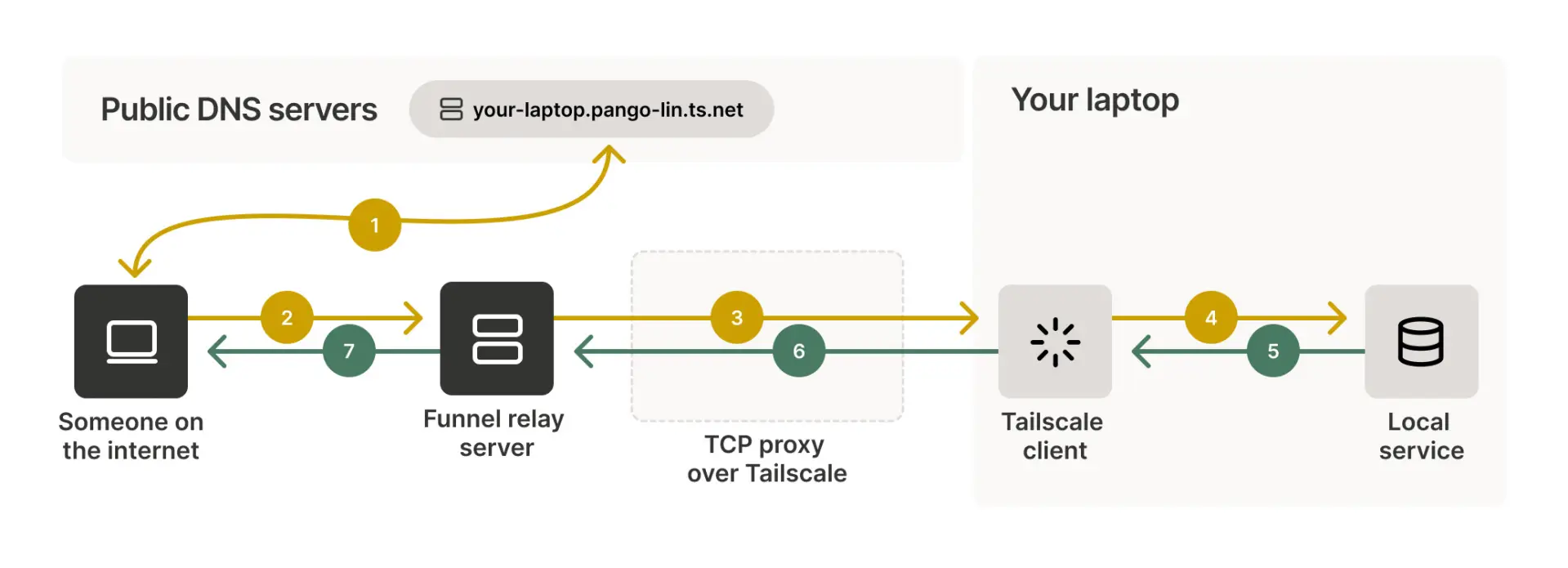 Illustration de la fonctionnalité de « Funnel » de Tailscale via WireGuard
(Crédit photo : Documentation Tailscale)
Illustration de la fonctionnalité de « Funnel » de Tailscale via WireGuard
(Crédit photo : Documentation Tailscale)
Concernant GitLab, c’est un outil merveilleux, lui aussi découvert au travail. Depuis mes débuts dans le développement, j’utilisais GitHub. Mais c’est quoi GitHub et GitLab ??? En résumé, quand vous créez un site Internet ou une application, vous écrivez du code. Pour conserver des versions de votre code, l’archiver, le partager et collaborer avec d’autres développeurs, vous utilisez un système de contrôle de version, comme Git. GitHub et GitLab sont des plateformes qui hébergent des dépôts Git, c’est-à-dire des espaces avec lesquels vous pouvez stocker votre code, gérer les versions, collaborer avec d’autres développeurs, etc. GitHub est la plateforme la plus populaire, gratuite d’accès et possédée par Microsoft depuis quelques années maintenant. Elle est utilisée par des millions de développeurs dans le monde entier pour héberger leurs projets open source et privés. GitLab est une alternative à GitHub, qui offre des fonctionnalités similaires, mais qui est plus orientée vers les entreprises et qui propose une version auto-hébergée que vous pouvez installer sur votre propre serveur, et c’est évidemment ce que j’ai fait. 😎
Non parce que GitHub, c’est bien gentil, mais j’en profite seulement parce que j’ai encore des offres étudiantes et je sais que cela ne durera pas toute une vie. Pour y remédier et après avoir utilisé GitLab en auto-hébergement pendant deux ans, j’ai voulu sauter le pas : profiter de toute la puissance d’une instance GitLab auto-hébergée, sans restriction, sans payer pour déclencher des déploiements, sans payer pour des fonctionnalités supplémentaires, etc. C’était une solution idéale pour moi et un investissement à long terme pour mon infrastructure et mes projets. Limite, le reste de l’installation des machines virtuelles, c’était du bonus. Là, on entrait dans le cœur du sujet et sur quoi je me battais : migrer mes projets personnels vers GitLab et faire l’ensemble de mes opérations critiques dessus en remplacement de GitHub. Après avoir installé GitLab, j’ai pu facilement migrer mes dépôts, paramétrer mon instance comme je le voulais, avec des fonctionnalités comme le registre de conteneurs pour héberger mes images Docker, les runners pour faire du CI/CD et aussi GitLab Pages.
 Capture d’écran du dépôt GitLab hébergé sur GitLab en version 18
(Crédit photo : Moi-même)
Capture d’écran du dépôt GitLab hébergé sur GitLab en version 18
(Crédit photo : Moi-même)
OK, temps mort. Explications.
Déjà, qu’est-ce qu’un registre de conteneurs ? C’est quoi Docker ? Docker, c’est un système de conteneurisation qui permet de faire tourner des applications dans des conteneurs isolés, c’est-à-dire que chaque application Web fonctionne de manière isolée, dans son propre environnement, avec ses propres dépendances, ses propres configurations, etc. Cela offre la possibilité aux développeurs de créer des applications installables sur n’importe quel système ou machine exécutant Docker facilement, de manière consistante et rapide. C’est une évolution directe des anciennes façons de faire où il fallait, dans le meilleur des cas, et par application, créer une machine virtuelle pour chacun de ses projets avec une base de données, un serveur Web et tout le tintouin. Avec Docker, il est tout à fait possible de faire tourner plusieurs conteneurs dans une même machine virtuelle, ce qui permet de faire du multi-tenant de manière plus efficace en termes de ressources et de coûts. Donc un registre de conteneurs, c’est un espace de stockage pour les images Docker.
Pour GitLab, quand vous créez vos images, il faut bien les enregistrer pour les utiliser plus tard, ailleurs, sans les recréer à chaque fois. Oui, parce qu’une image Docker, c’est un peu comme une recette de cuisine : elle contient toutes les instructions pour créer un conteneur, c’est-à-dire une application Web fonctionnelle, et cela peut prendre du temps et des ressources. Donc il est plus efficace de créer une image une fois, de l’enregistrer dans un registre de conteneurs et de la réutiliser autant de fois que nécessaire. C’était le point d’orgue de mon système de déploiements automatisés, autrement dit que le CI/CD de GitLab, qui permet de faire des déploiements automatisés de mes applications Web à chaque fois que je fais une modification dans mon code, s’appuyait sur ce registre de conteneurs pour créer des images Docker à partir de mon code et les déployer automatiquement sur mes machines virtuelles.
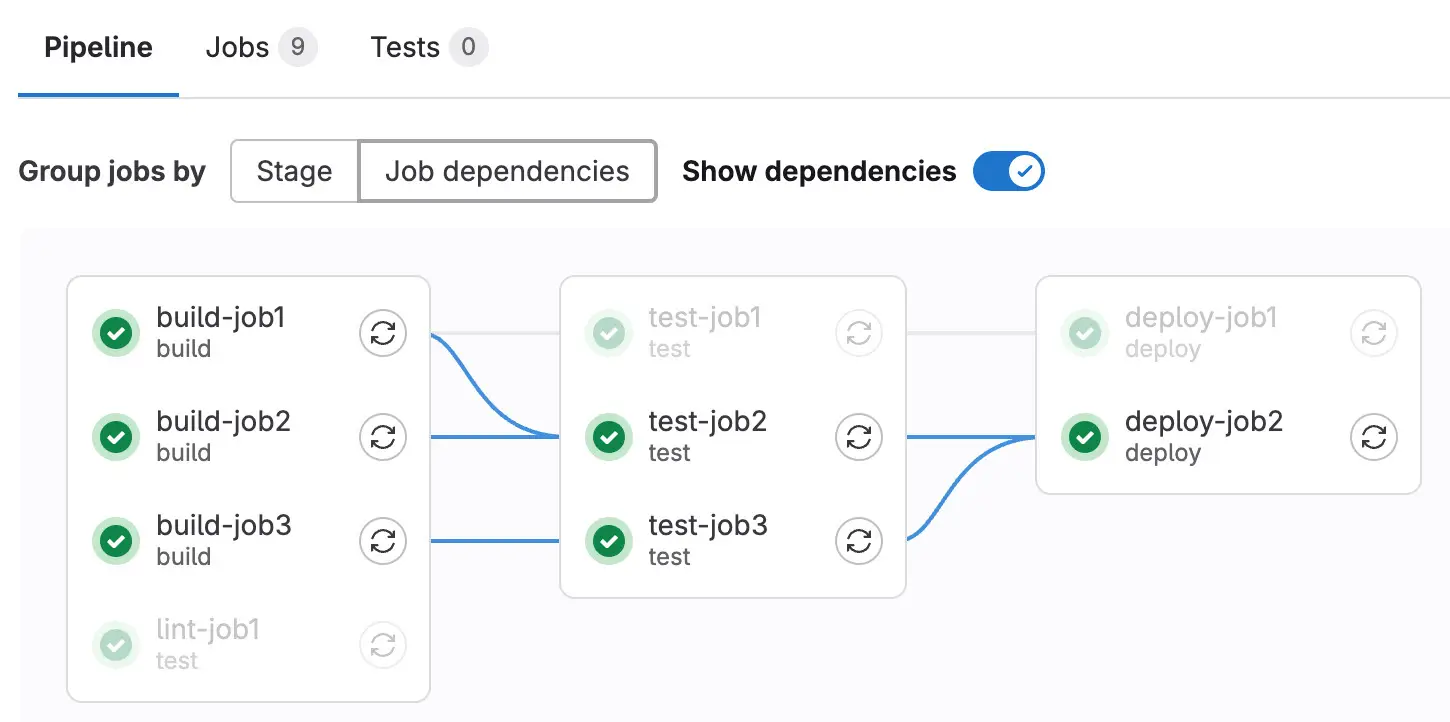 Illustration du fonctionnement d’un pipeline CI (Continuous Integration)
(Crédit photo : Documentation GitLab)
Illustration du fonctionnement d’un pipeline CI (Continuous Integration)
(Crédit photo : Documentation GitLab)
Enfin GitLab Pages, c’est… eh bah, vous y êtes en fait. Spoiler : l’adresse du blog a changé si vous ne l’avez pas remarqué 🙂. Et vous êtes actuellement en train de lire un article sur GitLab Pages. OK, j’arrête et je vous explique. Dans le monde des applications Web, en dehors de Docker et du déploiement d’applications Web sur un serveur qui doit tourner en permanence, vous pouvez aussi construire de manière unique votre site Internet. Par exemple, mon blog est construit une fois. Pourquoi ? Eh bien le contenu ne change pas avec le temps et seules mes modifications sont responsables de son évolution. Il n’y a pas d’interactions avec les utilisateurs, pas de base de données, pas de fonctionnalités dynamiques, etc. C’est ce qu’on appelle un site Internet statique, c’est-à-dire un site Internet qui ne change pas en fonction des interactions des utilisateurs ou du temps, mais qui est construit une fois et servi tel quel à chaque visite.
C’est une technique fantastique, respectueuse de la vie privée et de l’environnement. Limite, je pourrais vous donner le site Internet construit pour que vous puissiez lire mon blog même hors connexion si vous le souhaitez. Donc en résumé, GitLab Pages, c’est une fonctionnalité de GitLab qui permet de construire et de déployer des sites Internet statiques à partir de votre code source. C’est une solution idéale pour héberger des blogs, des portfolios, des sites Internet personnels, etc., sans avoir à se soucier de la gestion d’un serveur Web ou d’une base de données. C’était parfait pour moi.
Reprenons.
Précédemment, mes applications Web persos étaient toutes construites et vérifiées via un pipeline CI/CD sur GitHub Actions, qui est le système de déploiement continu de GitHub, mais qui est limité dans sa version gratuite, notamment pour les projets privés, et qui ne me permettait pas, par exemple, de mettre mes images Docker dans un registre de conteneurs privé, faire des vérifications de mon code, des audits de sécurité et tout un tas de choses qu’on fait dans le monde du développement pour s’assurer que l’environnement de production ne plante pas parce que Titouan, 24 ans, en première année d’alternance en cycle d’ingénieur, n’a pas vu qu’à la ligne 3739 du fichier database.ts il avait oublié de remplacer le mot de passe par défaut password1234.
Bref, c’était crucial et essentiel pour moi. OK, je suis de mauvaise foi, car j’aurais pu très largement sortir ma carte bancaire et cracher de l’argent à Microsoft. Mais quel était l’intérêt pour moi de payer alors que je payais déjà une infrastructure capable de le supporter ? Bon, j’avais des doutes à propos des ressources à allouer à la machine virtuelle, parce qu’il est gourmand ce coquin. En fin de compte, et après avoir migré mes projets les plus actifs, sauf mon raccourcisseur d’URL (oui encore lui…), j’ai pu exploiter une bonne partie des fonctionnalités et j’ai enfin réussi à atteindre un fonctionnement stable, professionnel et satisfaisant pour moi, avec des déploiements automatisés, des vérifications de code, des audits de sécurité, etc. En plus de cela, j’ai pu enfin faire le ménage sur mes projets personnels, en créant des tickets pour les faire évoluer et tout un tas de choses que je ne voulais pas faire dans GitHub par peur d’atteindre une limite ou de ne plus revenir en arrière.
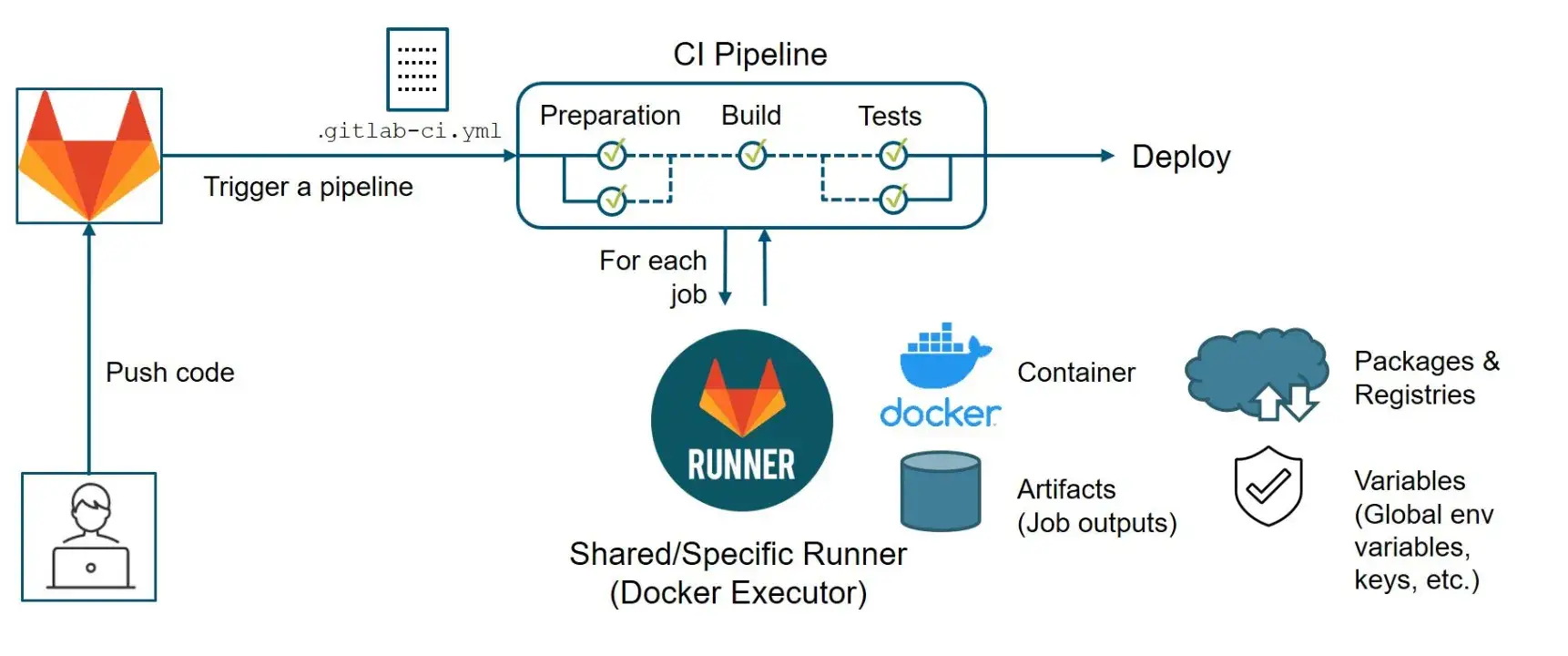 Illustration de l’utilisation du registre de conteneurs pour les déploiements
(Crédit photo : Neha Saini)
Illustration de l’utilisation du registre de conteneurs pour les déploiements
(Crédit photo : Neha Saini)
Après GitLab et pour mes déploiements, j’ai donc créé une machine virtuelle qui était en charge de toutes mes applications Web persos. Elle était utilisée par GitLab pour les déploiements et, pour cela, j’ai utilisé le fantastique outil appelé Ansible. Ansible, qu’est-ce que c’est ? Eh bien, c’est aussi un livre de recettes, mais cette fois, vous dites comment votre site Internet est déployé sur une machine. C’est-à-dire que vous écrivez une recette pour dire : « Hey, pour déployer mon site Internet, il faut d’abord installer Docker, ensuite, il faut créer un conteneur à partir de l’image Docker que j’ai dans mon registre de conteneurs GitLab, enfin, il faut configurer le serveur mandataire pour que les requêtes qui arrivent sur Internet soient redirigées vers ce conteneur ». Bref, c’est quelque chose de génial, car déjà cela remplace mon script bash de la honte et tout est fait de manière automatique. Je me sens enfin comme un vrai professionnel (et heureusement que je ne suis pas payé pour faire ça, sinon je serais dans la merde).
Beaucoup de mots pour dire que j’ai achevé cette migration à 95 % grâce à une bonne dose de virtualisation, de bonnes pratiques et beaucoup d’huile de coude. Il reste évidemment deux, trois projets qui seront migrés plus tard, mais qui ne sont pas immédiatement importants pour l’objectif du 1er avril.
La sauvegarde et la sécurité
Haha, vous l’attendiez, alors j’utilise encore mon script bash pour sauvegarder mes données ? Spoiler : non. Et vous savez quoi ? Merci encore Proxmox, oui parce que cet outil fantastique qui déjà vous masse les pieds, vous fait des câlins, vous fait du café, etc., offre la possibilité de faire des instantanées et des sauvegardes périodiques de vos machines virtuelles. OK, qu’est-ce qu’un instantané ? Un instantané, ou snapshot, c’est comme un point de restauration au bit près de votre machine virtuelle à un instant précis. Par exemple, je vais intervenir sur mon instance GitLab pour supprimer un fichier que je juge suspect, mais j’ai peur d’endommager l’instance et la dernière sauvegarde remonte à il y a quelques heures maintenant. Pas de souci : je prends un instantané de mon instance, je fais ma modification et si ça casse ? Je restaure à l’identique comme si je n’y avais jamais touché, c’est magique.
L’autre fonctionnalité de Proxmox, ce sont les sauvegardes périodiques, c’est-à-dire que vous pouvez programmer des sauvegardes régulières de vos machines virtuelles, par exemple tous les jours à 2 h du matin, et Proxmox s’occupe de faire les sauvegardes pour vous, sans que vous ayez à vous en soucier. Il y a plusieurs types de sauvegardes où vous avez la possibilité de faire des sauvegardes pendant que vos machines virtuelles sont en fonctionnement, les « suspendre » ou les arrêter pour gagner en intégrité, etc. Et tout ce petit monde se retrouve ensuite sur l’un des deux disques durs de la machine dans un répertoire spécialement conçu par Proxmox.
Moi, de manière automatique, via rclone, je synchronise les instantanés et les sauvegardes de manière chiffrée avec trois points de sauvegarde. Un point chez AWS S3 à Paris, un chez OVH Strasbourg et un physiquement à Cannes 🌴. Le troisième, c’est juste mon disque dur (déconnecté) sur mon ordinateur perso qui me sert de redondance locale au cas où le monde part en troisième guerre mondiale, au moins j’aurais une sauvegarde de mes données chez moi, ce n’est pas si mal pour un début d’apocalypse. Pour les deux autres, qu’est-ce qu’un bucket S3 et c’est quoi le S3 ? S3, c’est un service de stockage en ligne proposé par Amazon Web Services (AWS) qui permet de stocker et de récupérer des données à tout moment et depuis n’importe où sur Internet. Un bucket S3, c’est un conteneur de stockage dans S3, c’est comme un dossier dans lequel vous pouvez stocker vos fichiers, vos sauvegardes, etc.
C’est une solution idéale pour stocker des sauvegardes de machines virtuelles, car elle offre une grande durabilité, une grande disponibilité et une grande sécurité pour vos données via la redondance. Rclone est alors l’outil compatible idéal pour synchroniser mes sauvegardes de Proxmox avec mes buckets S3 : il permet de faire du chiffrement, de la synchronisation, de la gestion des versions, en gros tout ce qu’on peut avoir besoin pour gérer efficacement ses sauvegardes dans le cloud.
 Logo du service S3 chez Amazon Web Services
(Crédit photo : Amazon Web Services)
Logo du service S3 chez Amazon Web Services
(Crédit photo : Amazon Web Services)
Oui, parce que les sauvegardes, c’est important, la sécurité l’est encore plus. Parce que c’est bien gentil d’héberger toutes ces données, mais en ne dépendant plus de tiers vient alors la question de la résilience de ses données. Je l’avoue, si je perds mon serveur, actuellement, j’ai mes sauvegardes, tout ira bien. Il y a une certaine époque où, si je perdais tout, eh bien, je perdais ma vie. Aujourd’hui, je sauvegarde mes photos, vidéos, films et tout un tas de souvenirs que, si je perds, je pense que je perdrai une partie de moi-même, de mon histoire, et ça je ne veux pas le subir, sous aucun prétexte. Donc, je préfère avoir plusieurs sources de sauvegarde qui me permettront de tout récupérer et de remonter tout cela en cas de problème plutôt que d’avoir une seule source de sauvegarde qui pourrait être compromise, corrompue ou perdue. Pour le commun des mortels, ce rôle est assumé par Google, Microsoft et Apple et compagnie, mais même s’ils ne sont pas sans failles, ils offrent une sécurité et une résilience quasi parfaites pour leurs utilisateurs. Je ne dis pas que mes solutions de sauvegarde sont aussi sécurisées et résilientes que celles de ces géants du numérique, mais j’ai fait de mon mieux pour mettre en place des solutions de sauvegarde qui sont à la fois sécurisées, résilientes et efficaces pour mes besoins personnels.
En termes de sécurité, eh bien, j’ai essayé de mettre en place de bonnes pratiques, en chiffrant les sauvegardes, en limitant les surfaces d’attaque sur la machine. Par exemple, l’interface d’administration possède une restriction IP qui ne peut pas être atteinte même par mes machines virtuelles, machines virtuelles elles-mêmes inaccessibles par défaut depuis Internet. Mes données les plus sensibles ne sont plus chez Google, mais chez nos amis les Suisses de chez Proton, et je pense que je vais éviter 99 % des problèmes de sécurité. Resteront les attaques informatiques très sophistiquées qui dépendront d’un logiciel obsolète, d’un manque de sécurisation de ma part ou juste de moi-même qui, par exemple, ferait compromettre l’un de mes ordinateurs personnels, mais bon, ce n’est pas Mr.Robot hein. Bref, je reste vigilant, je garde un œil sur les mises à jour que je fais de manière périodique sur l’ensemble des machines virtuelles et sur Proxmox lui-même et je reste au courant des actualités en matière de sécurité en cas de gros pépin.
Le résultat final
C’est la fin ! Merci de l’avoir lu, et honnêtement, je suis vraiment fier d’être arrivé jusqu’ici, fier de moi d’avoir trouvé les ressources et la motivation pour faire tout ça, fier d’avoir suivi ma passion et mes envies de faire mieux que de rester dans ma zone de confort. Personnellement, je ne pensais pas que j’allais faire tout ça, je pensais que j’allais faire une migration basique, mais au final, j’ai fait une migration complète de mon infrastructure, avec une refonte totale de la manière dont je gère mes projets personnels, de la manière dont je gère mes sauvegardes, de la manière dont je gère la sécurité de mon infrastructure, etc. Bref, c’était un projet ambitieux, mais qui m’a permis de faire évoluer mon infrastructure vers quelque chose de plus moderne, plus efficace et plus sécurisé.
Surtout, j’ai mûri davantage sur le fait qu’il est important de faire les choses correctement, de prendre le temps de comprendre les outils que j’utilise, de ne pas sous-estimer les ressources nécessaires pour faire les choses correctement afin de ne pas se retrouver dans une situation où on a une infrastructure qui ne fonctionne pas correctement, qui est instable, qui est vulnérable. C’est plutôt satisfaisant, gratifiant et quel plaisir de voir mes amis qui s’y connaissent un peu dans ce domaine me dire que j’ai fait du bon travail, que j’ai une infrastructure plutôt solide pour mes humbles connaissances. Si je devais dire quelque chose au Florian du passé, ce serait : n’abandonne pas, tu vas y arriver, tu vas faire du bon travail, tu vas apprendre beaucoup de choses, tu vas faire des erreurs, mais c’est normal, c’est comme ça qu’on apprend et que tu vas devenir quelqu’un de meilleur dans ton boulot.
Est-ce que c’est chose faite ? Est-ce que j’ai atteint mon objectif ? Oui, je pense que j’ai atteint mon objectif, je vous laisse en juger même si je suis au tout début de mon aventure. Il me reste un tas de choses à découvrir sur Proxmox, la gestion des machines virtuelles et autres outils que je pourrais utiliser pour automatiser tout ça. Par exemple, Terraform. Terraform, qu’est-ce que c’est ? C’est un outil, comme Ansible, mais qui se concentre plutôt sur la gestion de l’infrastructure, c’est-à-dire que vous pouvez utiliser Terraform pour créer, modifier et supprimer des ressources dans votre infrastructure, comme des machines virtuelles, des réseaux, des bases de données, etc. Je ne l’ai pas encore pris en main, mais j’ai hâte de le découvrir pour pouvoir créer des machines virtuelles sans intervention de ma part, avec la configuration prête à l’emploi et sans faire certaines tâches de manière répétitive. Bref, vous avez la vision, comme dirait une certaine personne.
 (Crédit photo : Huseyn Naghiyev)
(Crédit photo : Huseyn Naghiyev)
La suite ?
Cet article est terminé, vous pouvez retirer vos lunettes de geek 🤓 et autres accessoires ridicules. La dernière fois, j’ai menti : vous vous attendiez à lire quelque chose sur les espaces de travail comme Sundesk, finalement je vous ai tartiné sur Proxmox, la virtualisation et tout un tas de trucs techniques, mais c’était pour la bonne cause, c’était pour vous faire découvrir un peu plus en détail ce que j’ai fait ces derniers mois !
Pour le prochain article, pas de date, très probablement en mai où on parlera soit des offres d’emploi et du marché du travail OU de ce qu’il se passe en ce moment aux États-Unis d’Amérique. Oui, parce que dans un cas comme dans l’autre, j’ai des choses à dire, on verra bien et peut-être que vous lirez un tout autre article parce que j’aurai envie de vous parler d’autre chose. Bonne journée ou soirée pour les intimes ! 😊

